
Non-assisted scene calibration: an innovative impact on sports analysis

Written by:
Izan Leal30 de Abril de 2024
While traditional sports video analysis has been a reliable method, its reliance on manual processes becomes a bottleneck as the amount of data to be analyzed expands. With the proliferation of high-definition cameras and the availability of vast archives of sports footage, the sheer volume of data can overwhelm traditional analysis methods. Moreover, the demand for timely insights and real-time feedback adds further pressure to expedite the analysis process. In response to these challenges, the sports industry increasingly turns to innovative technologies and methodologies to streamline the analysis workflow.
Building upon our previous post on assisted scene calibration, this blog post will delve into the latest advancements in autonomous scene calibration that eliminate the need for human intervention, thereby boosting performance and alleviating the workload of analysts. Join us as we uncover the intricacies of these state-of-the-art techniques and their transformative impact on sports analysis.
Keypoint detector models
As mentioned in the previous post, key points are needed to compute the homography matrix that enables the player reprojection. The user carried out this gathering task, but some automated alternatives use traditional and AI computer vision approaches.
One of the most commonly used traditional models is SIFT (Scale-Invariant Feature Transform), which detects distinctive points invariant to scaling, rotation, and illumination changes. However, one significant limitation is its computational complexity, especially when dealing with large datasets or high-resolution images.
Another approach is Convolutional Neural Networks (CNNs), which have emerged as a powerful tool, leveraging deep learning techniques to automatically learn and extract meaningful features from raw data. CNNs exhibit remarkable accuracy in keypoint prediction, line segmentation, or area masking, which can then be processed to obtain the input points of the calibration model. They have been extensively applied in various sports analytics tasks. However, despite being powerful tools for many tasks, they have some drawbacks. One significant limitation is their reliance on large amounts of labeled data for training. Training CNNs requires substantial computational resources and time, making them impractical for applications with limited data or computational resources.
In our analysis of Convolutional Neural Network (CNN) models for automatic scene calibration, we found that most CNNs need lots of labeled data for a good dimensionality representation. Autoencoders, however, lessen the dimensionality of the data by learning compact and relevant representations of the input. This makes autoencoders particularly effective for keypoint detection in varied scenarios.
Scene calibration architecture
The proposed approach for obtaining non-assisted scene calibration consists of a hybrid system that combines the Autoencodes (Deep Learning) for key point prediction with RANSAC algorithm (classical Computer Vision) for homography matrix computation.

Figure 1. Hybrid approach architecture
The encoder-decoder model will now use a mesh of 91 points instead of the 28 points from the manual method, focussing on soccer field line intersection points. This mesh is distributed uniformly across the image and allows for coverage of soccer scenes with insufficient field line intersection points.
|
Figure 2. Field lines intersection as key points. |
Figure 3. Uniformly distributed 91 key points mesh. |

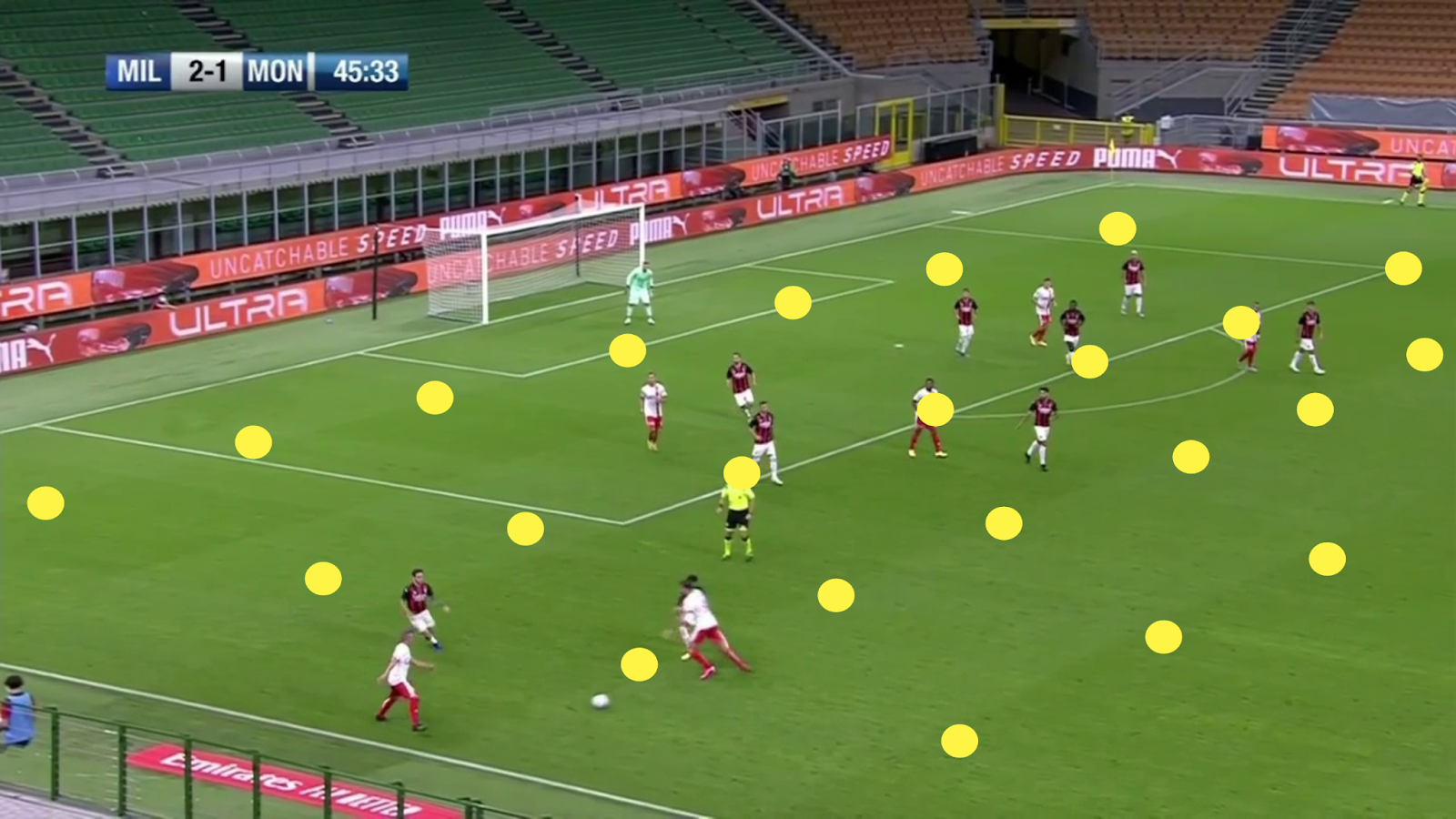
Despite the system being more accurate and requiring almost no human interaction to generate the video analysis, the user still needs to input the field size as a reference for real-world matching. However, this task is only required once per video and can even be kept if the videos are from the same field.
Keypoint extraction
For the keypoint extraction, the image is fed into the encoder-decoder model, also known as the autoencoder. The first part of the model, the encoder, transforms the input data into a lower-dimensional representation, also known as a latent space. It learns to extract meaningful features and patterns from the input, compressing it into a compact representation. This reduction in dimensionality helps capture the most essential information while discarding irrelevant details. This latent space is rich in information but lacks structure. Further steps are required to interpret these features.
In this scenario, the decoder takes the encoded representation and endeavors to reconstruct the original input data structure. It learns to generate a representation resembling the original input by mapping the low-dimensional latent space back to the original data space.
During training, autoencoders minimize the reconstruction error between the input and the reconstructed output. By doing so, they force the model to learn a compressed representation that captures the essential characteristics of the input data.
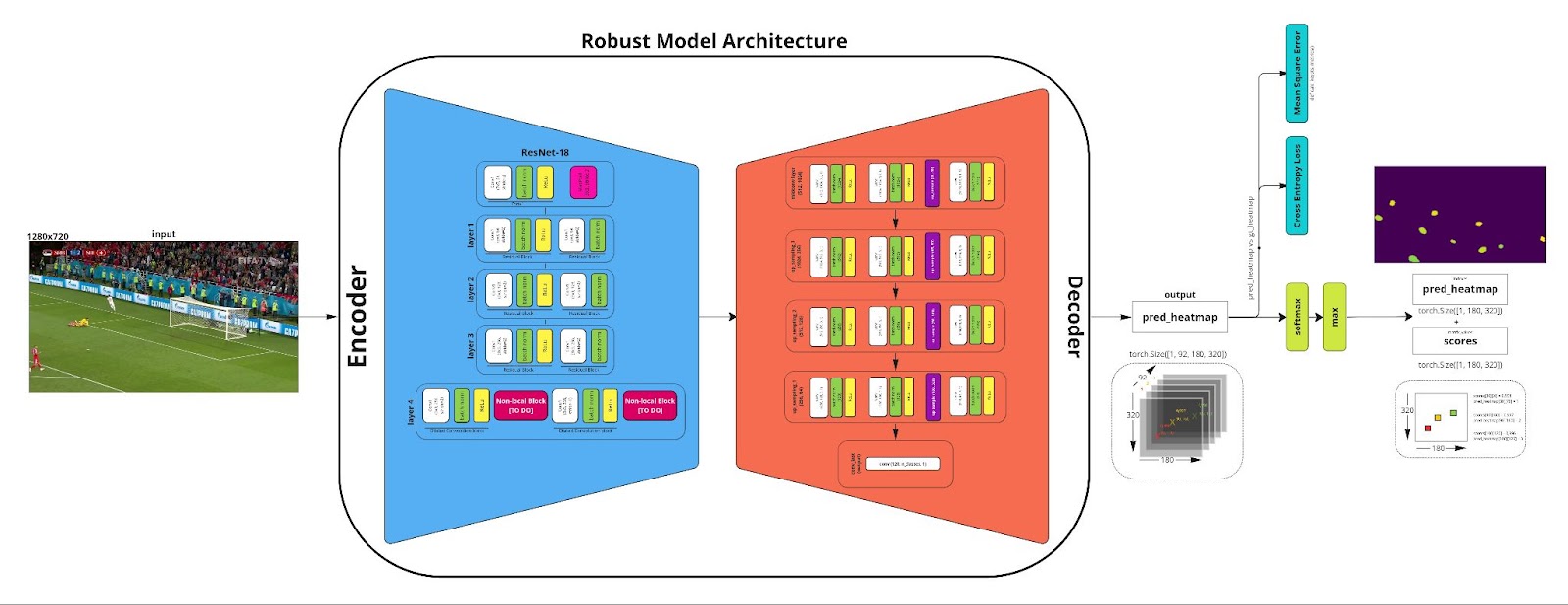
Figure 4. Encoder-Decoder Model Architecture.
We performed numerous training experiments with our model, systematically adjusting various hyperparameters. Unlike the model's trainable weights, updated during training, hyperparameters remain constant and influence how the model learns. Therefore, meticulous selection and tuning are crucial to determine the optimal combination that yields the best results.
Model Training and validation
The training experiments were conducted using customized datasets containing real and synthetic images. These datasets have various combinations of image types and a different number of images extracted from SoccerNet, Public Soccer Worldcup, and synthetic data, which is covered in a previous post.
After training the modes with different parameters and datasets, the following results were obtained:

These results show the performance against the ground truth of the key points obtained with the autoencoder. However, even though these metrics represent the performance, they only evaluate the first part of the scene calibration system. This means that a small error in a keypoint detection can be amplified after the reprojection step.
This makes it necessary to evaluate the complete system performance more thoroughly.
Evaluation & Results
In assessing the effectiveness of the autonomous keypoint extraction model alongside the reprojection algorithm, we primarily focused on computing the mean absolute error, as it measures the disparity between the ground truth and the predicted reprojection values, which is the most representative metric to see how the system performs. To obtain this metric, two datasets comprise both real-world s (Figure 6) and synthetic (Figure 7) soccer field images. Additionally, these datasets will not only be used to obtain the mean absolute error but also to verify visually that the system works.

Figure 6. Evaluation dataset with real soccer images

Figure 7. Evaluation dataset with synthetic soccer images.
5 perspectives with 3 soccer field textures.
The obtained mean absolute errors in the real dataset (Figure 6) are presented in a box plot graphic (Figure 8). This enables us to assess and compare the different models in terms of their accuracy in estimating the key points positions and identify the best-performing model based on its ability to minimize the error.

Figure 8. Box Plots graphics for the best models of each dataset type.
Our findings have proven that the best-performing model (big_mix_0) can perform even better than a human in terms of precision, and it can generate sufficient points for the homography computation in all the images. The model performance can be seen further in (Figure 9).

Figure 9. Visual result of the best model (big_mix_0) predicting the evaluation dataset with only real images.
Conclusions
In conclusion, the non-assisted scene calibration has laid excellent results, demonstrating that the calibration process can be carried out successfully without human interaction at all. Additionally, positioning is more robust and accurate than human-assisted scene calibration, achieving better image warping, bird view, and player's heatmap.
Step into the future of computer vision. Reach out today here and unlock the potential of your projects!

