Blog
Stay Up to Date
Expand your Multimedia knowledge
Most Recent Posts
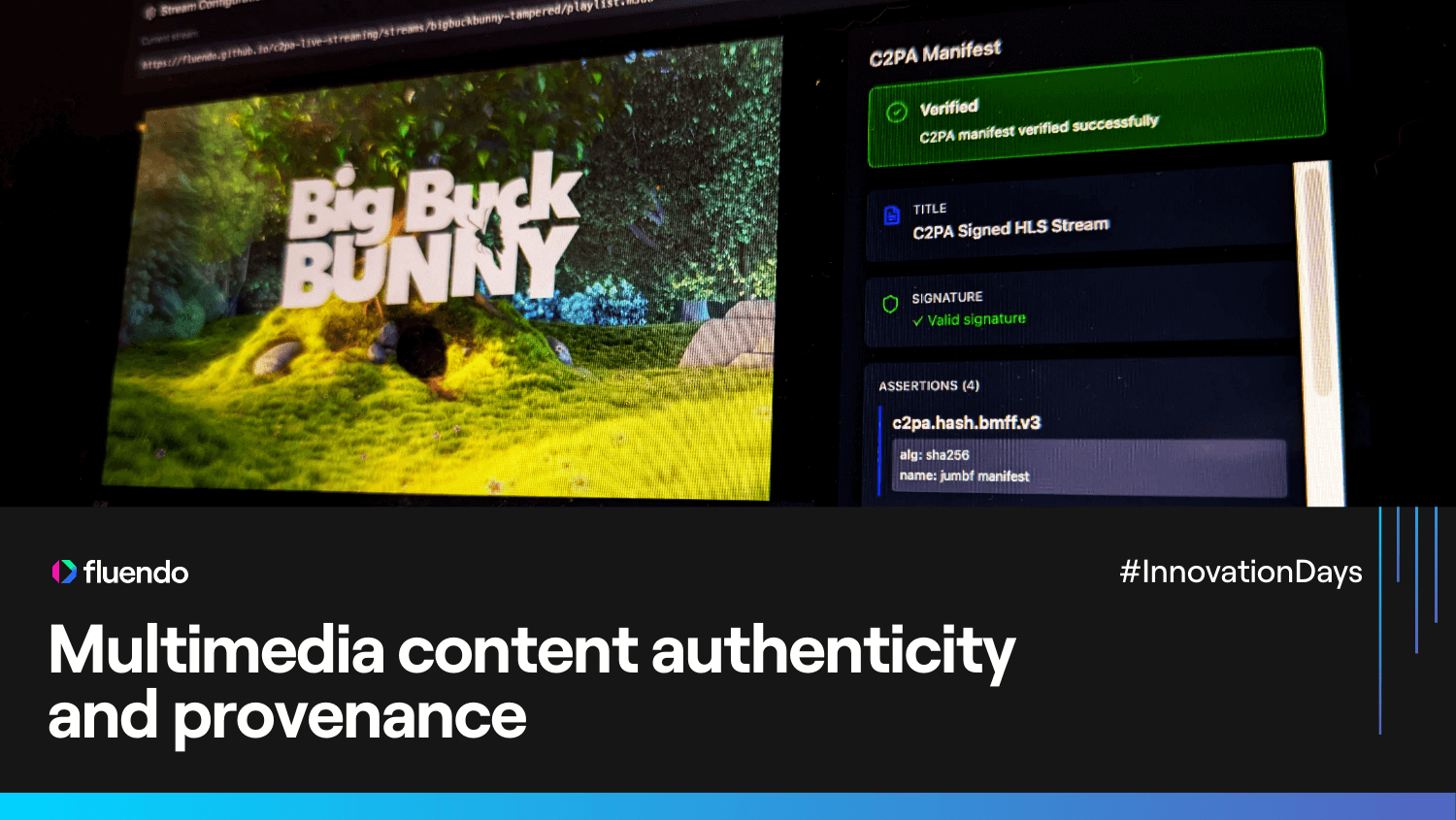
Multimedia content authenticity and provenance
Learn how Fluendo is tackling the deepfake crisis through multimedia content authenticity and provenance. Discover how C2PA standards and GStreamer are securing the future of live streaming."

Gst-Audit: The instrumentation tool for your pipelines
gstreamer, open-source, events, beaver
Enhancing video quality assessment in GStreamer - Encoder statistics and VMAF integration
codecs, gstreamer, outsource
Browse by
Announcements
Events
Open-Source
Broadcasting
DaaS & VDI
Sports
Video Surveillance
Beaver
Hype
Lynx
Owl
Raven
Anonymizer
Directshow-Enabler
FFmpeg Enabler
FFmpeg Enabler + Dolby Professional
Fluendo AI Plugins
Fluendo Codec Pack
Fluendo-Hbbtv-Sdk
Fluendo-Media-Center
Longomatch
Moovida
Oneplay-Codec-Pack
Oneplay-Dvd-Player
Remote Desktop Coding Tools
Bug-Fixing
Guidance
Optimization
Outsource
Staff-Augmentation
Training
Upstreaming
Application Development
Browsers
Codecs
GStreamer
Multimedia Edge AI
Multimedia content authenticity and provenance
Gst-Audit: The instrumentation tool for your pipelines
gstreamer, open-source, events, beaverEnhancing video quality assessment in GStreamer - Encoder statistics and VMAF integration
codecs, gstreamer, outsource
From GStreamer Web APIs to C2PA: 5 Projects from our latest Innovation days
events
Fluendo at the Core of GStreamer 1.28.0: Leadership in ORC and video quality measure with VMAF
gstreamer, open-source
Fluendo at MWC Barcelona 2026: Multimedia solutions for 5G, edge and telecommunications

IA-Veu building legal, ethical, and trustworthy AI voice technology in Catalan
multimedia-edge-ai
Fluendo and Spyrosoft BSG partner to develop AI-Powered solutions for sports video analysis and broadcast workflows
broadcasting, sports, multimedia-edge-ai, announcements
Fluendo at ISE 2026: Solutions for the professional AV industry
bug-fixing, guidance, optimization, outsource, staff-augmentation, training, upstreaming
Fluendo at GStreamer Conference 2025 in London
gstreamer, events, open-source, owl
Fluendo x Intelion: Low-latency live video streaming and recording for law enforcement
broadcasting, application-development, gstreamer, outsource
Enhancing mobile video playback: Lessons from a real-world GStreamer project
ai, software-services, gstreamer, multimedia-edge-ai, application-development, codecs, bug-fixing
Raven: A 100% GPU-driven AI inference framework for real-time video and graphics
ai, multimedia-edge-ai, fluendo-ai-plugins, raven
NMS-Raster: Post-processing bounding boxes using the “G” in GPU
sports, multimedia-edge-ai, gstreamer, fluendo-ai-plugins, raven
Next Stop: GStreamer Conference 2025 in London, UK
gstreamer, events, open-source
A month after IBC 2025: Inspired and ready for what’s next

Advertisement detection in multimedia content with artificial intelligence
broadcasting, multimedia-edge-ai, application-development, outsource
Fluendo AI Plugins v1.0.4: The power of real-time AI anonymization
fluendo-ai-plugins, anonymizer
Real-time 4K face anonymization benchmark (GStreamer plugin)
broadcasting, video-surveillance, automotive, multimedia-edge-ai, gstreamer, events, fluendo-ai-plugins, anonymizer, raven
AI-based soccer metrics extraction app
sports, multimedia-edge-ai, gstreamer, outsource, raven
Virtual avatars optimized for AMD GPUs in video games
hardware-manufacturer, multimedia-edge-ai, gstreamer, outsource, raven
Alpha channel support for VVC/H.266 in vvenc and GStreamer
government, codecs, gstreamer, outsource
Intelligent parking spot occupancy detection
automotive, multimedia-edge-ai, optimization
Flexible video streaming and recording platform: Architecture and features
broadcasting, application-development, gstreamer, outsource
Fluendo's STREAM project: Final results from SPIRIT Open Call
government, gstreamer, codecs
Recasting and recording system enhancement
broadcasting, application-development, gstreamer, outsource
Fluendo awarded 6G-XR Open Call 3 grant to pioneer LCEVC-Powered holographic streaming
daas-vdi, gstreamer, codecs
Fluendo awarded SPIRIT Open Call 2 grant: Introducing AIVATAR
daas-vdi, gstreamer, codecs, fluendo-codec-pack, fluendo-ai-plugins, remote-desktop-coding-tools, raven, lynx
Privacy-preserving AI video surveillance with edge intelligence
video-surveillance, multimedia-edge-ai, gstreamer, events, fluendo-ai-plugins, raven
GStreamer Spring Hackfest 2025
gstreamer, codecs, browsers, events, open-source, owl
How Fluendo and Serenity* Star bring multimodal AI to business with computer vision
multimedia-edge-ai, raven
Low-latency marine streaming with Rust and GStreamer
broadcasting, application-development, gstreamer, outsource
Our latest GStreamer course for multimedia development
military, gstreamer, training
From a basic OpenCV script to a robust GStreamer-based solution
broadcasting, gstreamer, outsource, open-source
GStreamer course in Rust
broadcasting, application-development, training
Recasting and Recording System (RRS) a case study by Fluendo
broadcasting, application-development, gstreamer, outsource
Transforming ideas into AI-driven solutions: Join Fluendo at MWC 2025!
events, announcements
A glimpse of Fluendo at ISE 2025!
events, announcements
Fluendo expands audio capabilities with Dolby AC3 Professional decoder integration in our codec solutions
broadcasting, codecs, fluendo-codec-pack, ffmpeg-enabler, ffmpeg-enabler-dolby-professional
Your next big idea starts here: Join Fluendo at ISE 2025
events, announcements
Fluendo Becomes a Licensed Implementation Partner for Dolby Audio Professional
broadcasting, codecs, announcements, fluendo-codec-pack, ffmpeg-enabler, ffmpeg-enabler-dolby-professional
Next Generation Audio in MPEG-DASH - Personalized experience with Dolby AC-4, DTS-UHD and MPEG-H 3D Audio
broadcasting, gstreamer, events
Image superresolution with GStreamer
broadcasting, video-surveillance, sports, multimedia-edge-ai, gstreamer, events, fluendo-ai-plugins, raven
Face Anonymization with GStreamer
broadcasting, video-surveillance, automotive, multimedia-edge-ai, gstreamer, events, fluendo-ai-plugins, anonymizer, raven
4K real-time face anonymization GStreamer plugin benchmark
broadcasting, video-surveillance, sports, education, multimedia-edge-ai, gstreamer, events, fluendo-ai-plugins, raven
Fluendo at GStreamer Conference 2024 in Montréal, Canada
gstreamer, events, open-source, owl
Automate quality control with AI-Based Flaw Detection from Fluendo
hardware-manufacturer, multimedia-edge-ai, guidance
Synthetic data generator for AI chroma upsampling
daas-vdi, codecs, multimedia-edge-ai
GstWASM: The Open-Source project for GStreamer development in the Web
gstreamer, browsers, open-source, events, owl
Beyond numbers: a lesson in market research from Innovation Days
events
Next Stop: GStreamer Conference 2024 in Montréal, Canada
gstreamer, events, open-source, owl
MPEG-5 LCEVC in remote desktop streaming
daas-vdi, codecs, remote-desktop-coding-tools, lynx
How to cross-compile GStreamer for embedded systems
gstreamer, application-development, guidance
Upcoming Release 2.0.0 of Fluendo HW Codecs
daas-vdi, gstreamer, fluendo-codec-pack
Don’t miss Fluendo at IBC 2024 in Amsterdam!
broadcasting, events
Fluendo turns 20 years of coding the future of multimedia technology
announcements
Fluendo Open-Sources TTML Plugin to Empower the GStreamer Community
broadcasting, gstreamer, outsource, open-source, fluendo-codec-pack
Integrating Automated Testing in Multimedia
video-surveillance, gstreamer, codecs, outsource
Reducing video latency for GStreamer filters in digital microscopes
hardware-manufacturer, gstreamer, codecs, optimization
GStreamer Training for Application Development
gstreamer, application-development, training
Non-assisted scene calibration: an innovative impact on sports analysis
sports, multimedia-edge-ai, raven
Assisted scene calibration for sports analysis
sports, multimedia-edge-ai, raven
Improving AI-based Football Detection and Tracking with Transfer Learning
sports, multimedia-edge-ai, raven
GStreamer and Gaussianblur: Divide and conquer
hardware-manufacturer, gstreamer, embedded-devices, optimization
MWC 2024, here we go!
events
Navigating ISE 2024: A Remarkable Journey!
events
Barcelona Calling: Join Fluendo at ISE 2024!
events
GStreamer Training: from the first pipeline to handling threads
automotive, gstreamer, training
GStreamer development with Meson and VSCode
gstreamer, application-development, open-source
GStreamer Python Bindings for Windows
open-source
GStreamer Conference 2023 recap
gstreamer, open-source, events
How can LLM help us be more productive?
multimedia-edge-ai, events
HYPE: HYbrid Parallel Encoder
gstreamer, open-source, hype
Capture the best shots and metadata with our GStreamer PoC
unmanned-vehicles, gstreamer, codecs, application-development, guidance
Innovating Market Intelligence with AI and Data Analysis
multimedia-edge-ai, events
Improving on-device ML inference performance with compilers
ai, multimedia-edge-ai, raven
GstWASM: GStreamer for the web
gstreamer, browsers, open-source, events, owl
Born from an Idea: Unveiling Fluendo's Innovation Days
events
Next stop: GStreamer Conference 2023 in A Coruña!
gstreamer, open-source, events
Video codec optimized for desktop virtualization with LCEVC
daas-vdi, codecs, remote-desktop-coding-tools, lynx
Lights, camera, innovation! Fluendo on the road to the IBC 2023
broadcasting, events, remote-desktop-coding-tools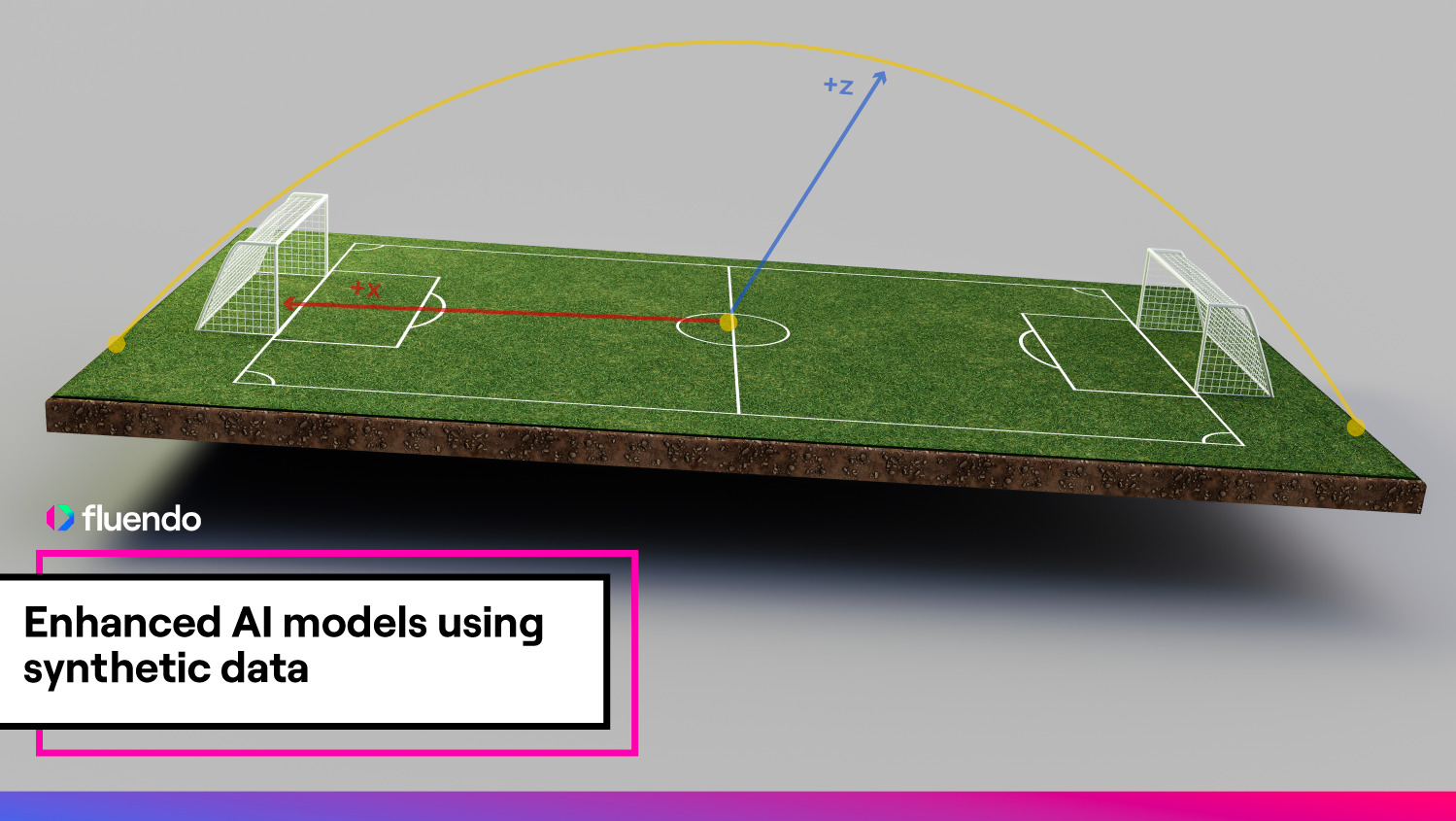
Enhanced AI models using synthetic data
sports, multimedia-edge-ai, raven
Putting closer Fluendo Hardware decoders to the GStreamer community memories
gstreamer, codecs, announcements, fluendo-codec-pack
GStreamer Training: Practical Approach for Beginners with Real-World Examples
gstreamer, codecs, application-development, training
Revolutionizing Video Management: a GStreamer Project on Windows
open-source
Open-source libva driver with vdpau backend powered by Fluendo
codecs, browsers, upstreaming, open-source
Don’t touch my memory
hardware-manufacturer, gstreamer, codecs, application-development, bug-fixing
Fluster: A framework for multimedia decoder conformance
codecs, gstreamer, ffmpeg, open-source
GStreamer HackFest Autumn 2022
gstreamer, events, open-source
Fluendo is heading to the IBC 2022!
broadcasting, events
ONEPLAY DVD Player Product Discontinuation
oneplay-dvd-player
Fluendo Joins IGEL Ready Program
daas-vdi, announcements
GStreamer Conference 2019
gstreamer, events, open-source
GStreamer Spring Hackfest 2019
gstreamer, events, open-source
DLL INJECTION
application-development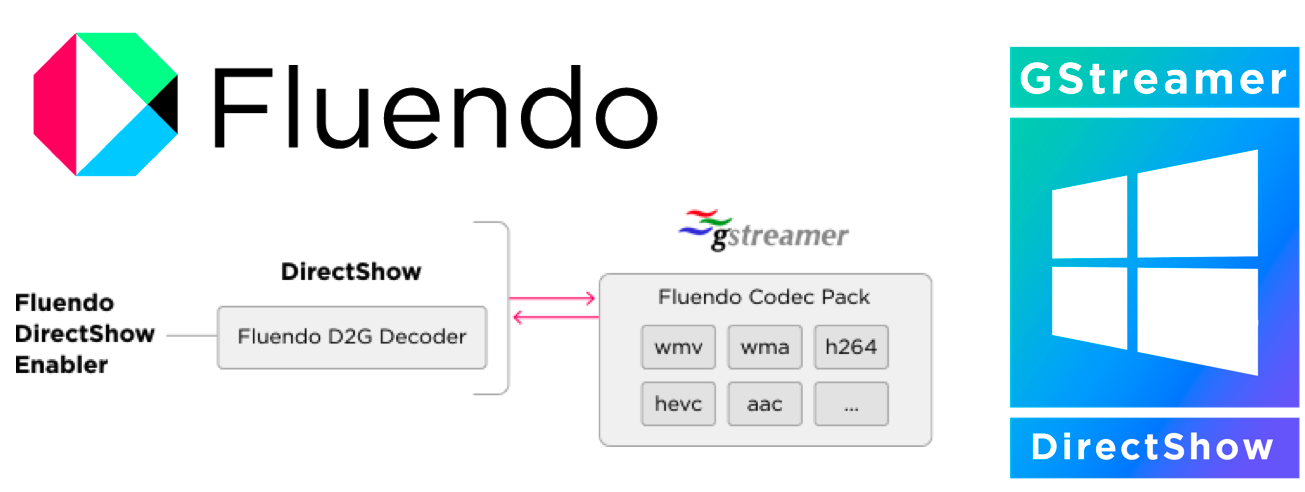
Introducing our bridge between DirectShow and GStreamer
gstreamer, directshow-enabler
Differences between GPL and LGPL when using licensed software
application-development, open-source, ffmpeg-enabler
Fluendo and SERAPHIC to showcase Android TV compliant HbbTV 2 SDK in IBC 2018
broadcasting, announcements, fluendo-hbbtv-sdk
How to use FFmpeg with GStreamer?
ffmpeg, gstreamer, ffmpeg-enabler
Fluendo and SERAPHIC develop fully compliant Digital TV browser solution for Linux and Android TV
broadcasting, fluendo-hbbtv-sdk
Citrix trusts the Fluendo Codec Pack to Enhance Multimedia Playback in their Networking and Virtualization Solutions
daas-vdi, announcements, fluendo-codec-pack
Douglas Brown spoke to Alex-Santos Fernández
daas-vdi, fluendo-codec-pack
Fluendo and SERAPHIC showcase fully compliant HbbTV 2.0.1 and Freeview Play solutions
broadcasting, gstreamer, browsers, fluendo-hbbtv-sdk
Fluendo, golden sponsor at the GStreamer conference
gstreamer, open-source, events
IGEL: A Superb Multimedia Partnership since 2009
daas-vdi, announcements, fluendo-codec-pack
HP trusts in the Fluendo Codec Pack for their new line of Linux-based Thin Clients
daas-vdi, announcements, fluendo-codec-pack
Codeweavers adds Fluendo’s ONEPLAY suite to its portfolio
software-services, oneplay-codec-pack
Fluendo joins the GENIVI Alliance to develop multimedia solutions in the automotive sector
automotive, announcements
Fluendo becomes an MPEG-DASH Licensee
broadcasting, gstreamer, codecs, announcements, fluendo-codec-pack
Fluendo provides legal multimedia software to a million thin clients
fluendo-codec-pack
Terra Soft today released Yellow Dog Linux v6.0 for Sony PS3, Apple G4/G5, and IBM System p. Built upon the CentOS foundation
operating-system-producer, announcements, fluendo-codec-pack
Fluendo increases sales by 9.3% in Q1 of 2016
announcements, oneplay-codec-pack
Fluendo announces turnover of 2,1M€ in 2015
announcements, oneplay-codec-pack
Fluendo Wins the Award 2015 NAB Best of Show for LongoMatch
announcements, events, longomatch
GStreamer Element in RDK Stack Opens New Possibilities for OEMs
gstreamer, codecs, oneplay-codec-pack
Despite Hype, HEVC Not Yet Ubiquitous
codecs, fluendo-codec-pack
Fluendo Announces Partnership With The Fraunhofer Heinrich Hertz Institute
announcements, oneplay-codec-pack
Fluendo Releases a New Version of its DVD Player
oneplay-dvd-player
Fluendo is proud to announce its Codec Pack 18, now supporting GStreamer 1.0 for several Linux Distributions
gstreamer, fluendo-codec-pack
GStreamer SDK Now Offers Support for Developing Multimedia Playback on Android
gstreamer
Fluendo Launches Moovida Universe, a Media Center Specially Optimized for the Second-Generation AMD A-Series APU
moovida
Fluendo Joins The Linux Foundation
announcements
Fluendo Attends GStreamer Conference to Present the Time Shifting Element
gstreamer, events, open-source
Fluendo Codec Pack Release 15: Now Supporting Hardware Acceleration for AMD XvBA
codecs, fluendo-codec-pack
Fluendo releases Moovida 2.1.0: Better Multimedia Management and Improved User Experience
moovida
Fluendo Joins Open Invention Network as a Licensee
announcements
Fluendo Releases SMD Elements for Intel® CE Media Processors
gstreamer
Fluendo Launches Moovida Pro, the Professional Media Center for Windows Operating Systems
moovida
Fluendo Codec Pack Release 11: Keeping Up with Technologies Fast Pace
gstreamer, codecs, fluendo-codec-pack
Fluendo Launches the DVD Player for Windows Operating Systems.
gstreamer, oneplay-dvd-player
Fluendo Launches the Ultimate Media Center for Linux Operating Systems
oneplay-dvd-player, fluendo-media-center
Fluendo announces Multimedia Solutions for Intel Moorestown Platform
codecs, fluendo-codec-pack
Fluendo Group Concerned over EC threat to open-source investment

Fluendo Launches the Long Awaited DVD Player for Open Solaris
oneplay-dvd-player
Fluendo Codec Pack Release 10: One Step Ahead to Reaching Excellence in Multimedia.
fluendo-codec-pack
Fluendo Launches the Long Awaited DVD Player for Linux, a Global Solution Built on GStreamer Multimedia Framework
gstreamer, oneplay-dvd-player
Fluendo announces the last release of its multimedia codec pack available on OpenSolaris, the open OS by Sun Microsystems
fluendo-codec-pack
Fluendo presents multimedia solution on Moblin, optimized for Intel® Atom™ processor at OSiM World 2008, Berlin
fluendo-codec-pack
Fluendo Codec Manager introduced in Mandriva Spring 2008 to help users enjoy their media files
operating-system-producer, fluendo-codec-pack
Fluendo co-founds The GNOME Mobile And Embedded Initiative
mobile, announcements
Fluendo announces Windows Media and MPEG codec support for GNU/Linux and Solaris
codecs, fluendo-codec-pack
Fluendo announces free MP3 audio decoding for GNU/Linux and Unix
codecs, fluendo-codec-pack
Fluendo announces public GStreamer plugin repository
gstreamer, open-source
Three new companies join the GNOME Foundation's Advisory Board
announcements, open-source
Nokia works with Fluendo on improving the GStreamer multimedia framework
gstreamer, announcements
Fluendo's investments in GStreamer lead to increased adoption
gstreamer, open-source
Fluendo funds Xiph.org for Vorbis and Theora RTP specifications
open-source
Fluendo announces official launch of the Flumotion Streaming Server project
open-source
Fluendo, GStreamer-based streaming media company, launched
gstreamer, announcements