
Improving on-device ML inference performance with compilers

Written by
Sergio SánchezOctober 11, 2023
The inception and implementation of Innovation Days at Fluendo have been directed towards nurturing creativity and fostering employee teamwork; one of the standout technological ideas selected to work during these days aimed to explore and unlock new potentialities in the realm of post-training optimization of machine learning inference at the edge, where computational power and efficiency are crucial.
Edge-AI and the Necessity for Post-Training Optimization of Models
Currently, Artificial Intelligence (AI) faces a variety of challenges centered on its increasing complexity, demand for real-time operations, and the need for privacy. Edge-AI emerges as a robust response, facilitating data processing on the device, thereby reducing latency and maintaining data privacy.
Edge-AI refers to the approach of bringing AI algorithms and data processing directly to where the data is created and consumed, namely, at the “edge” of the network, close to sensors and actuators, and away from centralized data centers. This approach seeks to overcome challenges associated with transferring large volumes of data to the cloud, reducing system response, ensuring privacy and security, and reducing the costs and bandwidth consumption associated with transmitting data to the cloud for processing.

Despite its advantages, Edge-AI also poses challenges. A fundamental one is optimizing the model to ensure efficiency on devices with limited resources. Post-training optimization techniques such as pruning, quantization, and compilation become essential to minimize model size and improve computational efficiency, thus allowing them to adapt to specific hardware.
- Pruning: This technique aims to eliminate parts of the model, such as neurons or connections, that have minimal impact on prediction to reduce computational complexity without sacrificing too much accuracy.
- Quantization: Quantization seeks to reduce the precision of the model’s weights and activations, mapping them to smaller integer value ranges to decrease model size and speed up inference without significant performance degradation.
- Compilation: In compilation, the model is transformed into an optimal form for the target hardware, rearranging operations to minimize latency or transforming model data and operations to leverage specific hardware instructions and capabilities.
Implementing these techniques allows AI models to be compact enough to operate in edge environments and maintain accurate predictions under these optimized conditions.
Compilation of ML Models
During the Innovation Days, we focused on the compilation of Machine Learning (ML) models, addressing detailed steps from creating a model to its efficient execution on specific hardware. Let’s break it down:
- Model Compatibility: The first step involves ensuring that ML models are in a format compatible with the compilers in question. This may involve converting models between different ML frameworks or modifying model architectures to be compatible with the compiler’s capabilities.
- Intermediate Representation (IR): In ML model compilation, the IR is an abstract form that represents the model in a manner that is independent of both the ML framework and target hardware. The IR is generated from the original ML model and serves as an abstraction layer, facilitating the translation of the model into a format that the specific hardware can efficiently execute.
- Optimization for Specific Hardware: After IR, we enter the domain of optimization, where the model is tuned to take full advantage of the capabilities of the target hardware, be it a Graphics Processing Unit (GPU), Central Processing Unit (CPU), or even specialized hardware like Tensor Processing Units (TPUs). This could involve reorganizing operations, merging model layers, and quantizing model weights to reduce computational complexity and increase inference speed.
Currently, various ML model compilers have been developed to facilitate this process, and they are strategically designed to deploy the models on specific hardware efficiently. Examples of these technologies include:
Hardware Vendor Compilers: Each major hardware vendor tends to offer their own compiler, tuned to their specific products:
- Nvidia’s TensorRT: Aimed at optimizing models for deployment on Nvidia GPUs.
- AMD’s ROCm and VitisAI: Providing an ecosystem to accelerate ML inference on AMD and Xilinx hardware.
- Intel’s OpenVino: Specializing in cross-platform inference optimization for Intel hardware.
Framework-Specific Compilers: Some ML development frameworks have their own set of compilers to facilitate inference:
- TFLite: Facilitates the inference of TensorFlow models on mobile devices and embedded systems.
- PyTorch Compiler and TorchScript: Allows converting PyTorch models into a format that can be more efficiently executed at runtime and also enables execution across different platforms.
Agnostic Compilers: Allow for greater flexibility by supporting multiple frameworks and devices.
- Apache TVM: It’s an open-source machine learning compiler framework for CPUs, GPUs, and machine learning accelerators. Its goal is to enable machine learning engineers to optimize and run computations efficiently on any hardware backend.
- XLA: The XLA compiler takes models from popular machine learning frameworks, such as PyTorch, TensorFlow, and JAX, and optimizes them for high-performance execution on various hardware platforms, including GPUs, CPUs, and machine learning accelerators.
Use Case: Optimization for High-Performance Inference on Edge Hardware
During the Innovation Days, after exploring the state-of-the-art cutting-edge technologies to guarantee the development of effective and practically optimized models. Specifically, for experimental exploration, we focus on Apache TVM due to its agnostic features and support for multiple frameworks and devices.
Exploring ONNX-Runtime in the Practice of AI Inference
In line with the post-training optimization of ML models during Innovation Days, the use of ONNX-Runtime also stood out as a fundamental pillar in the efficient implementation of AI inference. ONNX-Runtime presents itself as a versatile interpreter for Machine Learning models, supporting the open format ONNX, which ensures effective inference execution and also facilitates harmonious interoperability between different libraries and hardware through its ability to interact with various executor providers.
This technology has been essential, for example, in the Fluendo project to efficiently implement background removal models for a virtual camera application, automatically adjusting model execution to take advantage of available hardware and ensure fast real-time inferences, a critical need in live video processing use cases, such as video conferencing, live broadcasts or online gaming.
Although TVM has its own runtime to execute compiled models efficiently on various hardware platforms, the ONNX-Runtime ’executor provider’ for TVM takes on special relevance in our use case. This interaction ensures an optimized route to implement AI inference at the edge, guaranteeing not only efficient execution of the models but also effective adaptation to various hardware environments.
Promising Advances: Toward Optimal Implementation of Multimedia Edge-AI
Ultimately, the use of ONNX-Runtime has allowed us to execute the background subtraction model with inference times that are below 10 ms on the CPU, thus enabling real-time image processing on generic, non-AI-specialized HW, opening the door to its use on a wide variety of devices.
By integrating compilation with TVM, our results have evidenced significant performance optimizations, showing gains from 2x to 6x on our background removal model. This affirms the validity and efficacy of the implemented optimization and compilation techniques.
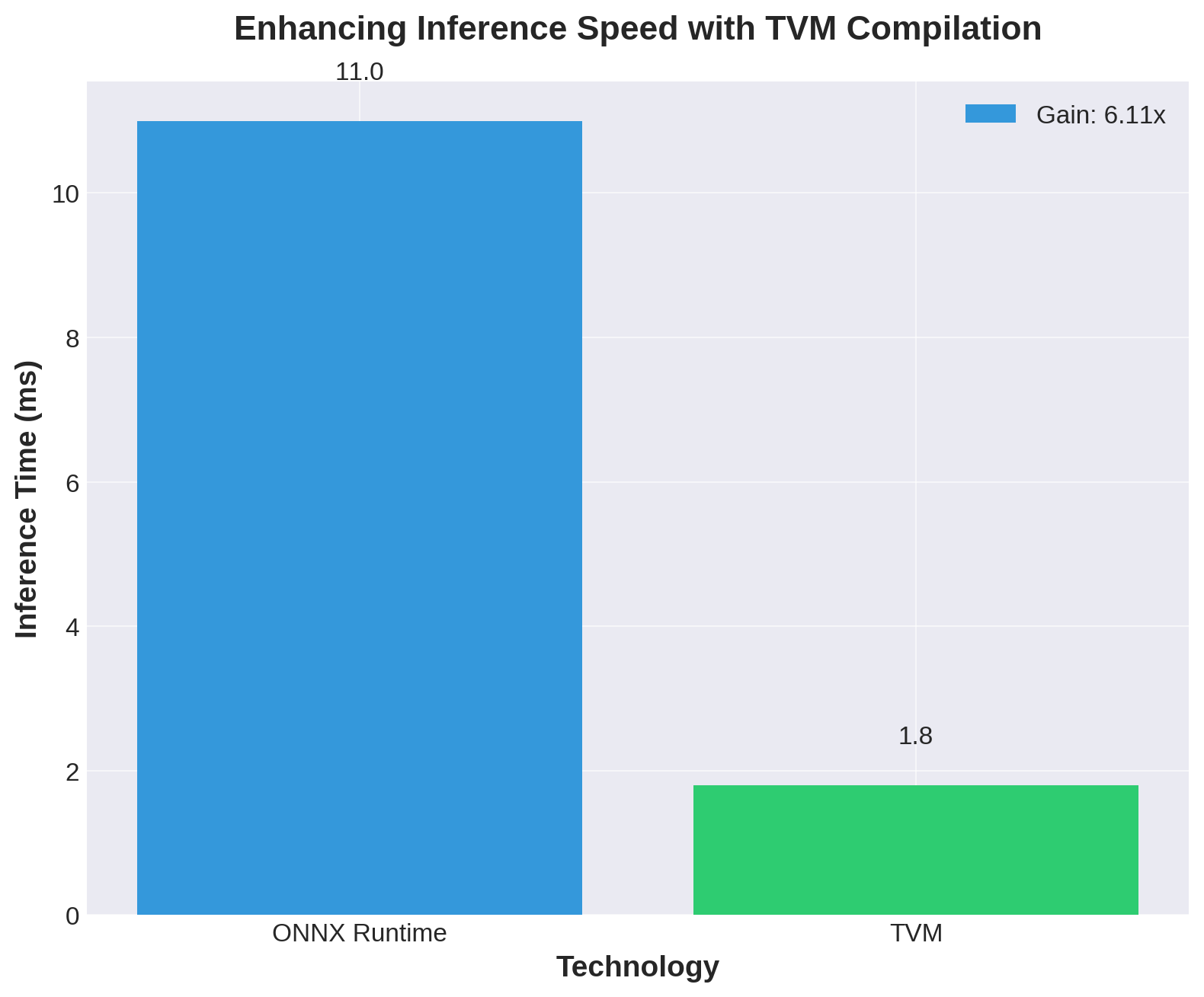
A comparison of inference times for a machine learning model using ONNX Runtime and after optimization with TVM. The significant speed-up, showcased by a 6x gain, underscores the efficacy of utilizing TVM for enhancing model inference performance on edge devices.
To wrap things up
At Fluendo’s Innovation Days, it has been demonstrated that the union of creativity and technology yields significant advancements, marking an important step towards deeper integration and continuous improvement of our advanced AI applications and ML model optimization.
These experiences document our efforts and discoveries in the realm of AI and reflect the constant drive toward innovation that characterizes Fluendo. We remain committed to navigating through ongoing technological and innovative advancements.
As for the next steps, at Fluendo, we continue to develop solutions for multimedia edge AI. Therefore, we are actively researching post-training optimization technologies to achieve optimized execution that is adapted to specific hardware and allows interoperability between different edge hardware. If you are interested in learning more or collaborating, please do not hesitate to contact our team here.